偷懒才能更好地工作。
Llama 3.1 刚刚发布,你是否已经尝试了呢?就算你的个人计算机是最近的顶尖配置,运行其中最小的 8B 版本可能也依然会有明显延迟。为了提升模型的推理效率,研究者想出了多种多样的方法,但其中很多都会让模型牺牲一些准确度。
近日,苹果和 Meta AI 的一个研究团队提出了一种新方法,可在保证准确度不明显下降的同时,将 Llama 2 预填充阶段的推理速度提升到原来的 2 倍以上,这或许能为 Llama 3.1 的加速提供一些启发。他们把这种方法称为 LazyLLM,即懒惰大型语言模型。

论文标题:LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
论文地址:https://arxiv.org/abs/2407.14057
那么他们是怎么让 LLM 偷懒的呢?要理解他们的方法,我们首先需要知道标准的基于 prompt 的 LLM 推理过程是怎样的。简单来说,该过程分为两个阶段:预填充和解码,如图 1 所示。
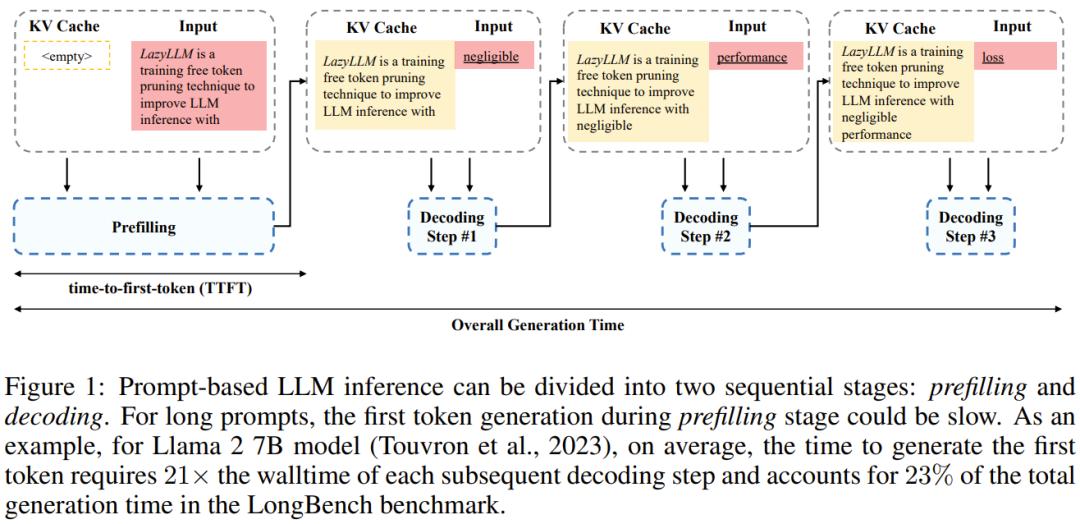
在预填充阶段,模型计算和保存 prompt 中每个 token 的 KV 缓存,并预测首个 token。我们将预填充阶段所耗费的时间称为「首个 token 时间(TTFT)」。
预填充阶段之后是解码阶段。在这个阶段,模型再次使用缓存的 KV 来迭代式地解码下一个 token,直到满足停止标准。
在预填充阶段,所有 Transformer 层都会使用 prompt 中的所有 token。当 prompt 较长时,TTFT 可能很慢,因为当前最佳的基于 Transformer 的 LLM 既深又宽,并且计算注意力的成本会随 prompt 中 token 数量而呈二次增长。举个例子,Llama 2(7B 版本)堆叠了 32 层 Transformer,模型维度为 4096。在这种情况下,TTFT 需要的 walltime 是每个后续解码步骤的 21 倍,在 LongBench 基准上这些时间大约占用了总生成时间的 23%。
因此,要让 LLM 推理高效进行,优化 TTFT 是非常关键的步骤。
尽管 LLM 推理优化方面是一个活跃的研究领域,但很多方法关注的重心都是提升解码阶段的推理速度。研究者很少关注 TTFT 的改进。一些基于压缩的研究成果可通过减少 LLM 的大小隐式地提升 TTFT。
另一个研究方向是在静态的 Transformer 架构下实现对 TTFT 的改进。对于这个研究方向,很自然会引出一个问题:在生成首个 token 时,所有 prompt token 都必不可少吗?
图 2 给出了在 LongBench 基准上的 LLM 分析结果。
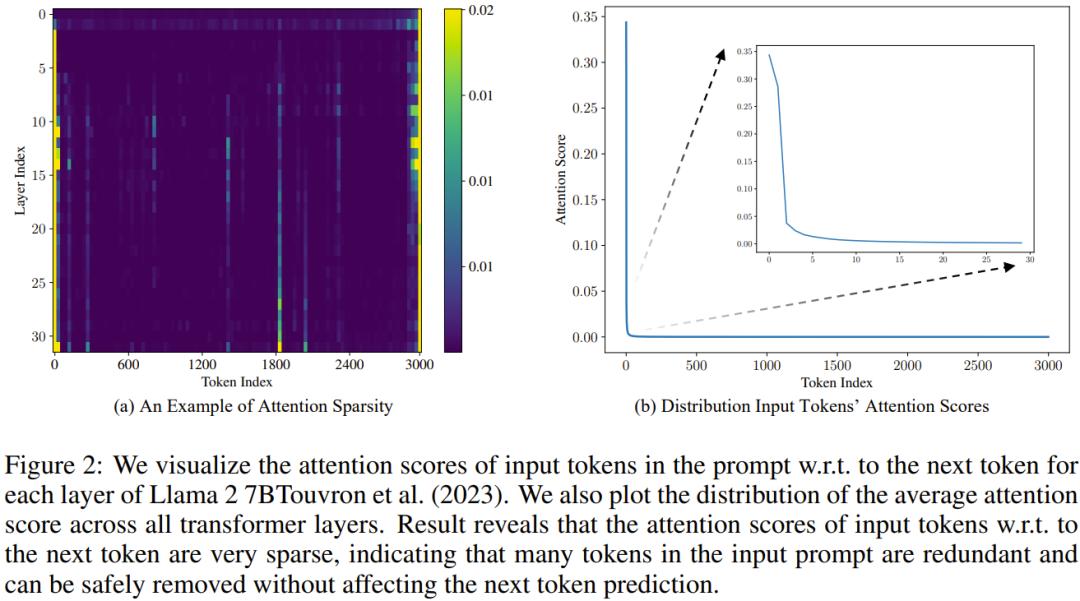
可以看到,对于首个生成的 token,输入 token 的注意力分数非常稀疏,这说明输入 prompt 中的许多 token 是多余的,就算移除也不会影响到下一 token 预测。这一观察正是该团队提出 LazyLLM 的基础。
LazyLLM 的优势包括适用范围广、无需训练、效果好。图 3 对比了标准 LLM 与 LazyLLM。

LazyLLM
图 4 展示了 LazyLLM 的整体框架。
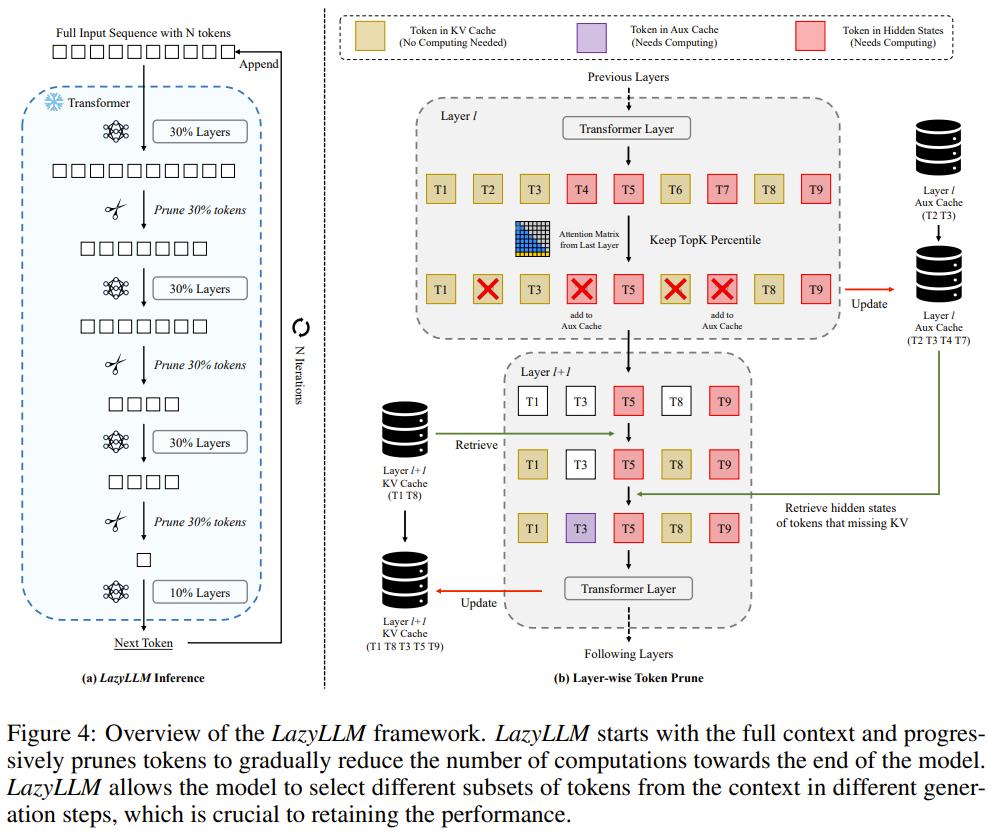
从完整上下文开始,LazyLLM 会逐渐对 token 进行剪枝,从而逐渐减少得到最终模型所使用的计算数量。请注意,LazyLLM 允许模型在不同的生成步骤选取不同的 token 子集,即便它们中的一些可能在之前的步骤中被剪枝了。相比于静态剪枝(一次性对所有 token 进行剪枝),动态剪枝会在每个生成步骤对下一 token 预测进行优化,这有助于维持模型的性能表现。
渐进式 token 剪枝
之前也有一些研究成功使用过 token 剪枝来优化 LLM 推理。但是,这些方法需要积累预测前几个 token 的完整注意力图,以便在剪枝开始之前分析 prompt token 的重要性。也因此,它们不适合用于降低 TTFT,因为它们在预填充阶段仍需要计算所有 KV 缓存。
相较之下,LazyLLM 「很懒」,会从推理的第一轮迭代(预填充步骤)开始,只计算对预测下一 token 重要的 token。
在第一轮迭代中,一大关键难题是确定各个 token 的重要性。受之前已有研究(其中表明 token 隐藏状态会在穿过 Transformer 层时发生演进)的启发,该团队的解决方案是在每个生成步骤使用逐层 token 剪枝。具体来说,他们是使用各层的注意力图来确定输入 token 对将要预测的 token 的重要性。
在计算了 token 的置信度分数之后,另一个难题是确定剪枝 token 的阈值。
具体来说,对于不同的层和不同的任务,该阈值可能会随注意力分数的变化而改变。该团队的解决思路是使用 top-k 百分位数选取策略。具体来说,如果一个 token 的置信度分数小于输入 token 中的第 k 个百分位数,便将其剪枝掉。一旦 token 被剪枝去掉了,它就不再参与所有后续层的计算。
也就是说,后续层使用的 token 是之前层所使用 token 的子集。
后面的实验表明,剪枝层的位置和剪枝的 token 数量不同时,也会导致性能发生变化。具体来说,对于同一 Transformer 层,随着被剪枝去掉的 token 越来越多,模型的性能也会逐渐下降。
他们还发现,相比于早期层的剪枝,在后期层执行剪枝时会得到更好的性能,这说明后期层对 token 剪枝的敏感度更低。为了更好地平衡速度与准确度,该团队使用了如图 4 所示的渐进式剪枝法,从而在早期层保留更多 token,然后在 token 流向后期层的过程中逐渐减少 token 的数量。
Aux Cache(辅助缓存)
预填充阶段没有 KV 缓存,每个 token 都表示成隐藏状态。因此,可通过移除已被剪枝 token 的隐藏状态来实现渐进式 token 剪枝。但是,要将渐进式 token 剪枝扩展到后续的解码步骤,却并不简单。原因是每个解码步骤都会使用预填充阶段计算的 KV 缓存来计算注意力。由于 LazyLLM 是在预填充阶段执行渐进式 token 剪枝,因此在某一层被剪枝的 token 的 KV 不会出现在下一层的 KV 缓存中。
这里提醒一下,LazyLLM 框架允许在每一步让每个生成步骤从完整的输入 token 序列中挑选一个不同的 token 子集,无论它们是否已在之前的步骤中被剪枝。举个例子,在接下来的解码步骤中,那些在 KV 缓存中不存在的已被剪枝的 token 可能会被重新选取出来用于计算注意力。在这种情况下,模型无法检索到这些 token 的 KV 缓存。
对此,一个基于直觉的解决方案是再让这些 token 通过该 Transformer 的起点。但是,这会导致对同一 token 的重复计算,并最终减慢整体的生成速度。
为解决这个难题,该团队在原有的 KV 缓存之外引入了另一种缓存:Aux Cache(辅助缓存)。
如果已被剪枝 token(如图 4 中 T4 和 T7)的 KV 并未出现在后续层的 KV 缓存中,则会由 Aux Cache 保存它们的隐藏状态以供后续迭代检索。
如图 4 所示,在每个解码步骤,每个 Transformer 层首先会检索过去 token 的 KV 缓存(如果存在的话)。对于那些不在 KV 缓存中的 token,则直接从其前一层的 Aux Cache 中检索它们的隐藏状态,而不必再次经过之前的层。Aux Cache 可确保每个 token 在每个 Transformer 层中最多被计算一次,还能确保 LazyLLM 最慢时也比标准 LLM 快。
实验
该团队在两个大型语言模型上检验了这种「懒惰」新方法:Llama 2 7B 和 XGen 7B。作为对比的标准 LLM 是同样的公开发布的预训练检查点模型,同时不进行任何附加训练。
实验基准是 LongBench,这是一个针对长内容理解的多任务基准。LongBench 基准包含 16 个数据集,涉及 6 个任务,包括单文档问答、多文档问答、总结、少样本学习、合成任务和代码补全。
评估指标是每种方法在 TTFT 加速与准确度权衡方面的效果和效率。
结果
表 1 给出了 LazyLLM、标准 LLM 和其它基线方法的 TTFT 加速和准确度结果。
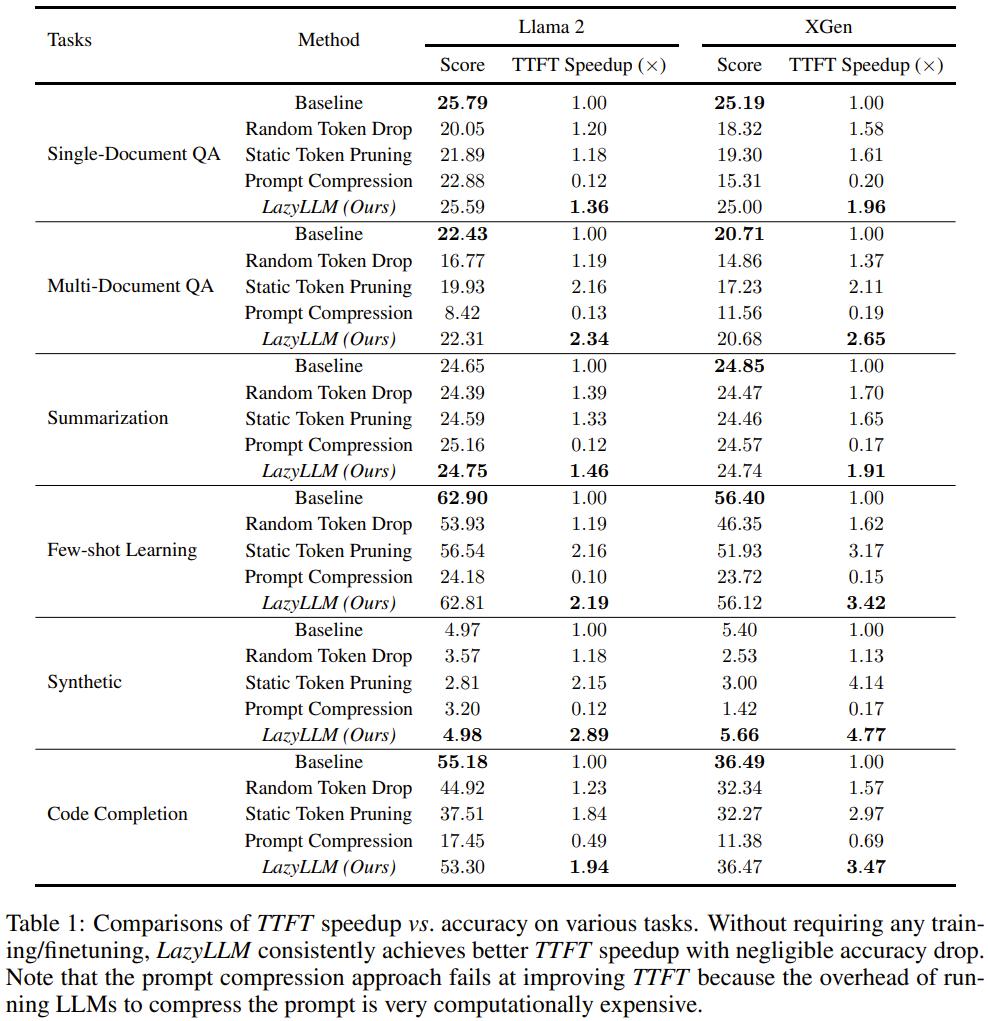
在此表中,baseline 是指标准 LLM 推理。random token drop 是指对 token 执行随机剪枝。static token pruning 是指在预填充阶段基于前面几个 Transformer 层的注意力方法来对输入 token 执行一次性剪枝。Prompt Compression 就是 prompt 压缩方法,也就是使用 LLM 去除输入上下文中的冗余。
从表 1 可以看到,LazyLLM 在 TTFT 加速方面全面优胜,同时准确度方面的下降基本可以忽略不计。需要指出,使用 LLM 来压缩 prompt 需要大量计算。因此,即使 Prompt Compression 能让推理速度更快,但其实际的 TTFT 却比标准 LLM 还长。
对总体生成速度的影响
为了评估新方法对总体生成速度的影响,该团队分析了计算使用的 prompt token 百分比和生成加速情况,见表 2。
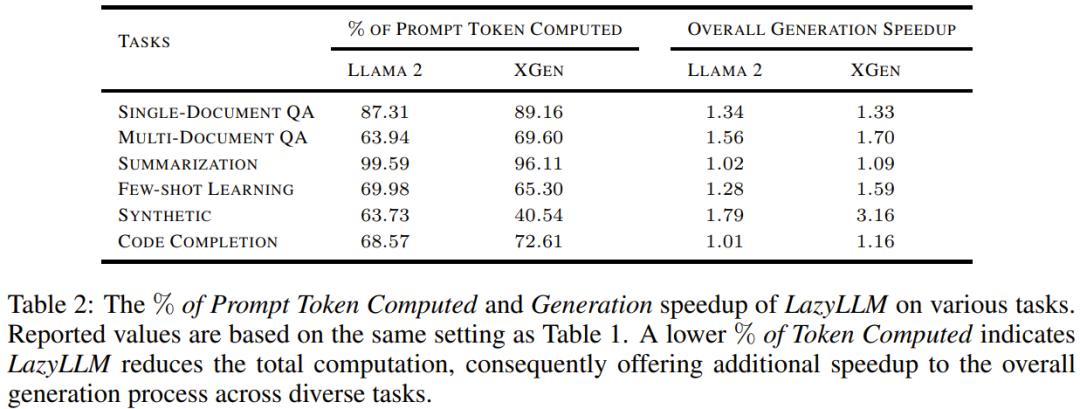
可以看到,LazyLLM 计算使用的 token 的占比总是低于 100%,这说明 LazyLLM 在生成结束时也没有用完 prompt 中的所有 token,但理论上讲该模型可以使用所有 token。这能为不同任务的整体生成过程提供额外的加速。
不同层的丢弃率
该团队也分析了剪枝层的位置和被剪枝 token 的数量的影响。结果见图 6。
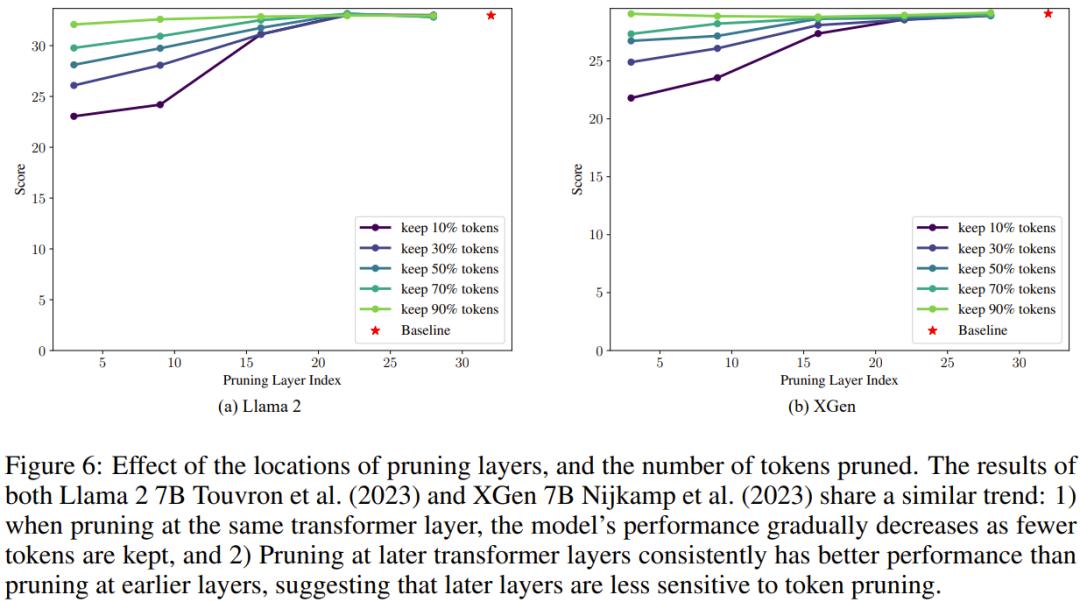
可以看到,当在同一 Transformer 层进行剪枝时,留下的 token 越少,模型的性能越差。这也符合我们的直观认知。此外,相比于在更前期 Transformer 层执行剪枝,在后期层进行剪枝会得到更好的性能,这说明后期层对 token 剪枝的敏感度更低。
基于这些观察,可以说渐进式 token 剪枝的效果得到了证明。
渐进式 KV 增长
最后,该团队也尝试了理解使用 token 剪枝逻辑的模型的内部情况。具体来说,他们想要了解 prompt token 中的累积使用比例以及相应的不被使用的比例。这种「累积 token 使用量」可以等价地定义成每一步的 KV 缓存 大小。图 7 给出了 LazyLLM 的每个阶段这些累积的 prompt token 使用量。
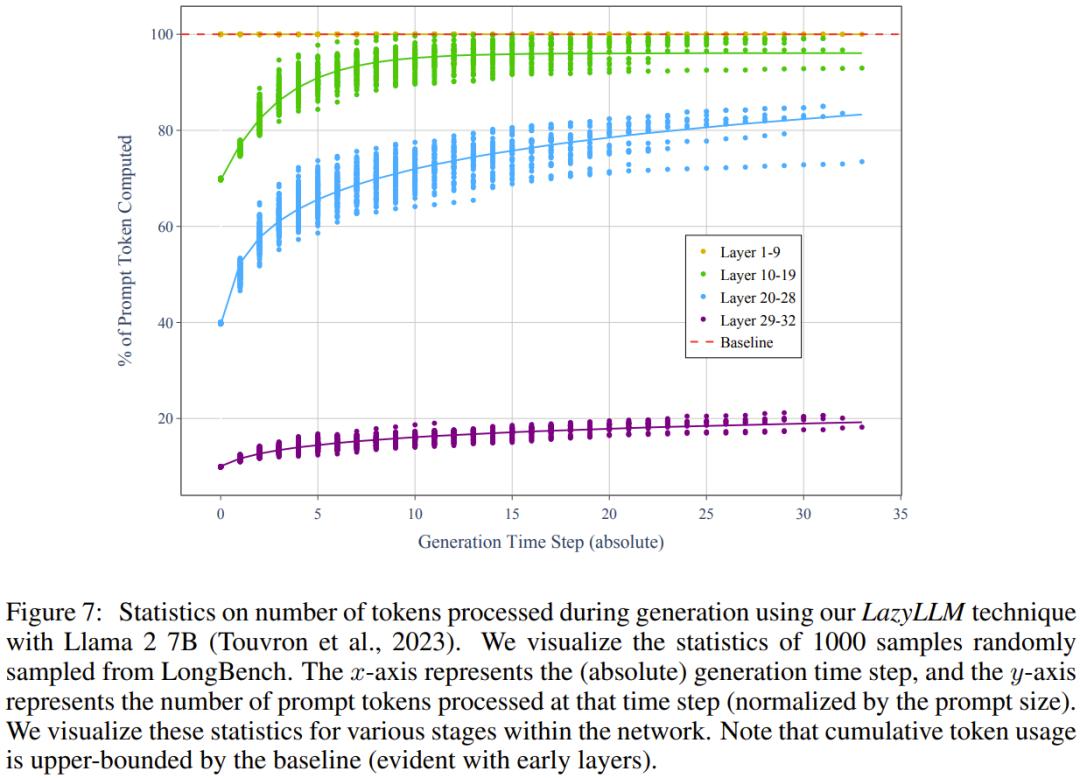
该结果支持这一假设:许多 token 永远不会被模型选择(即便理论上讲模型可以使用 prompt 中的所有 token。
考虑到模型依然能维持执行任务的准确度,因此可以得出结论:模型可以有效地丢弃不影响输出质量的 token。
